The Age of Embodied Intelligence: Why The Future of Robotics Is Morphology-Agnostic
This report was developed with significant research, analysis, and writing by Lux Capital Graduate Associate Ghazwa Khalatbari.
Over and over again, across unrelated lineages, life keeps reinventing the crab. Lobsters, king crabs, porcelain crabs - different ancestors, evolving into something crab-adjacent. Zoologists call it carcinization, a striking case of convergent evolution where unrelated species arrive at similar solutions to shared survival pressures [1]. Carcinization isn’t just a biological curiosity - it’s a story of form following function. The compact, armored, highly mobile crab-like body thrives because it adapts: to tidepools, coral reefs, sandy flats, deep-sea trenches, and everything in between.
We are now watching something similar unfold in robotics. AI has given machines brains: transformers that can perceive, plan, and reason at near-human levels. Those brains need bodies. But not any bodies. In the rush to push intelligence into the physical world, players from Tesla to Boston Dynamics are pouring billions into building bipedal humanoids – and while these systems may play important roles in human-centric environments, they are not the only path forward. Tomorrow’s most powerful machines won’t necessarily walk upright or look human.
At Lux, we believe the future of robotics won’t converge on a single form. It will diversify – into a proliferation of bodies shaped by task, terrain, and context. Robotics should follow the logic of evolution - not the ego of its creators - and hence not converge on humans, but on whatever embodiment best supports generalizable intelligence. The next giants will win by developing AI that generalizes across forms, learns across modalities, and acts with agility in the real world – regardless of shape. As Physical Intelligence demonstrates, embodiment matters, but conformity doesn’t.

The dream of humanoid robots predates the advent of robotics as we know it. From Maschinenmensch in the Metropolis to C-3PO, we’ve been conditioned to imagine artificial workers in our image - bipedal, symmetrical, expressive. Star Wars saw it coming: C-3PO mimics human traits yet fails under pressure; R2-D2, non-anthropomorphic and utilitarian, repairs starships under fire, disables battle droids, hacks enemy systems, and delivers the Death Star plans. That contrast reflects a core tension in today’s robotics boom.
Preceded by Honda’s ASIMO, NASA’s Robonaut, and Kawada’s NextAge, Tesla unveiled Optimus, a humanoid robot envisioned to replace humans in dangerous, dull, or repetitive labor. Musk claimed it would one day eclipse Tesla’s EV business [2]. While still early in its R&D lifecycle, Optimus remains a research-stage system: the prototypes shown to date are limited in capability, untested at scale, and have yet to see public deployment. Like many in the humanoid category, it faces steep challenges in cost, durability, and robustness in unstructured environments [3]. But it catalyzed a wave, from AI-native companies like Sanctuary AI, Figure, and 1X, to robotics-forward teams like Apptronik, Boardwalk Robotics, and Agility raising hundreds of millions to build “universal workers” modeled after ourselves, filling labor gaps in warehouses, kitchens, hospitals, and bedrooms. Even open-source entrants like K-Scale Labs and EngineAI joined the fray, alongside China’s Noetix and Unitree, pushing flashy demos from robot marathons to policing, eldercare, and backflipping androids. The pitch is clear: after all, we’ve built our world for human bodies. So why not design robots to walk the same hallways, and lift the same boxes?
This is the humanoid fallacy - the assumption that because our environments are human-centric, the most effective machines must be human-shaped. This mistake is a product of fiction, not function. It dismisses how evolution, engineering, and intelligence actually work. After all, computers are the furthest thing from humans - and yet billions of times more capable at tasks like memory, logic, and computation. Airplanes don’t flap their wings like birds. Submarines don’t swim the breastroke. Productivity doesn't demand mimicry; in fact, exponential innovation perhaps precludes it.
In robotics, imitating human form isn’t always a prerequisite, and can often become a limitation.
Let’s be real: Bipedal locomotion is energy-inefficient, slow, and mechanically complex. Automobiles are more than just Flintstone’s cars with more legs–spaceships more than rocket-fueled slingshots. Humanoid flagship robots like Boston Dynamics’ Atlas have a cost of transport ~3.3 over 15x less efficient than humans (~0.2) and up to 300x less efficient than wheels [4]. But even after decades of development, and despite its gymnastic feats and viral videos, Atlas has yet to be commercialized [5]. Instead, the company’s actual revenue comes from Stretch, a sturdy wheeled industrial robot built for box unloading in warehouses, and Spot, a compact, nimble four legged bot used for acoustic leak detection, predictive maintenance, and ultrasonic inspection, in manufacturing, construction, and public safety. With more than 1,500 Spots deployed in the field, Boston Dynamics has quietly validated our truth: in robotics, utility trumps anatomy.
The same lesson holds in consumer robotics. Consider robot vacuums: they succeed not because they resemble humans, but precisely because they don’t. Their low, disc-shaped bodies compress and slip under couches and beds, and their ultrasonic time-of-flight (ToF) sensors outperform human vision for edge detection and obstacle avoidance [6]. Meanwhile, we’re still years away from a humanoid robot that can simply detect dust, grip a vacuum, balance, bend, and navigate – if we need one at all
The problem with legs isn’t just cost - it’s misallocated and unnecessary complexity. Bipedal locomotion introduces compounding challenges: a higher center of gravity, instability on uneven terrain, and an enormous control burden for tasks as basic as walking. From a mechanical perspective, wheels and mobile bases provide a lower center of gravity, greater energy efficiency, and simpler dynamics for lifting and manipulation. For many industrial and service applications, wheels aren’t a compromise - they’re a competitive advantage. And yet, we continue to spend resources training bipedal systems that fall over in real-world environments. The robotics field remains captivated by balance control and reactive gait learning - when the far more urgent frontier lies in arms. If we redirected that focus toward high-precision actuators, variable impedance control, and data-efficient learning of fine motor skills, we could unlock capabilities far more economically and reliably than chasing humanoid locomotion. In the hierarchy of robotic utility, manipulation matters more than mobility, and arms - versus legs - will define the next leap forward (if we must adopt the anthropocentric vocabulary).
Nowhere is this clearer than in the long-standing challenge of the human hand. Five-fingered hands remain one of the most stubborn bottlenecks in robotics – not because we can’t build them, not because they’re inherently flawed, but because replicating human anatomy is technically complex. Companies like Sanctuary AI’s hydraulic Phoenix hand or Clone Robotics’ musculoskeletal Clone Hand aim to mirror the human hand with synthetic muscles and tendons, but struggle with precision, durability, and maintenance [7]. Five fingers mean five times the actuators, friction points, and failure modes – and we still lack materials that match the strength, compliance, cooling, and self-repair of the human body. That said, the human hand is an evolutionary marvel for fine-grained tasks – and in domains like surgery or assistive care, it may remain the gold standard. But for many industrial or general-use applications, full anthropomorphism is unnecessary. Simplified or task-specific end-effectors often outperform in reliability and cost. By contrast, projects like Stanford’s Roller Grasper V3 offer a smarter path: four steerable rollers on each fingertips with six degrees of freedom, enabling pitch-sensitive grasps that exceed human capabilities in some dimensions [8] [9]. It’s not a copy of the human hand – it’s an improvement on the concept that is focused on function, not form.
We don’t always need to replicate humans - we need to start from first principles and build from the ground up.
The real frontier in robotics isn’t replication - it’s decoupling intelligence from embodiment. Traditional development starts hardware-first: design a body, then train a brain to operate it. But that’s a brittle, slow-moving paradigm. When you tie a robotic “brain” to a single platform like Tesla’s Optimus, you inherit all its limitations: slow iteration cycles, high hardware costs, limited environmental diversity, and brittle real-world deployment. If you’re training on just one body, in just one warehouse, you’re bottlenecking intelligence at the source.
But what if we flipped the paradigm?
What if the goal wasn’t to build the perfect robot – but rather, to build the most generalizable intelligence?
That shift, from hardware-up to software-down, reframes what matters. The real question isn’t “What’s the optimal hardware form factor?” – it’s “how do I train flexible, capable intelligence?” And once you optimize for generalization, the importance of form fails away. In fact, learning across diverse embodiments – from off-the-shelf arms to drones to mobile bases – becomes a feature, not a compromise. Diversity enables transfer.
This is the core thesis behind one of our portfolio companies, Physical Intelligence (π or PI), which is redefining what generalization looks like in embodied AI. PI pursues a morphology-agnostic approach: one where robots learn and develop more flexible intelligence not by perfectly mimicking us, but by operating across bodies, tasks, and environments.
Instead of anchoring intelligence in a single robot morphology, PI embraces cross-embodiment transfer: the idea that robots trained on diverse embodiments (arms, mobile bases, static manipulators) can share and benefit from one another’s learning [10] [11] [12]. In effect, you can get positive transfer – or learning alpha – not just from more data, but from more varied data. A static arm in a factory, a mobile manipulator in an office, even a delivery robot navigating streets for Uber Eats - each becomes a source of training data for a general-purpose embodied model [13].
This approach mirrors the trajectory of large language models: LLMs like ChatGPT became powerful not through task-specific tuning, but by being trained on massive, heterogeneous corpora of text across the internet. They learn by predicting tokens - discrete chunks of text like words or subwords. The model’s job is to generate the next token in a sequence, based on patterns seen in its training data. Vision-language models (VLMs) extend this by grounding language in images: they can label objects, describe scenes, or answer questions about a photo. But both LLMs and VLMs operate in the realm of description. They interpret the world, but do not act in it.
Robotic learning also depends on scale – but there is no internet-scale dataset of physical interaction. The data must be generated, often through teleoperation: a human guides a robot through a task – grasping an object, wiping a counter, using a tool – and the robot records that demonstration as a trajectory of movements. These sequences become training data for imitation learning, where the robot learns to repeat and generalize from the behaviors it observed. Just like in language models, the system observes a sequence of tokens and learns to predict what comes next. But unlike LLMs, the tokens aren’t text – they’re actions: joint angles, end-effector delta movements, or torque vectors that directly control a robot’s limbs [14]. These models ground prediction in physical execution by taking in visual, textual, and proprioceptive inputs and outputting embodied action tokens – placing them in a third category known as Vision-Language-Action (VLA) models [15].
Physical Intelligence’s VLA models operationalizes the thesis that robotic generalization doesn’t require deploying fleets of identical humanoids, but rather aggregating data from multiple embodiments, tasks, and context. Given a prompt like “clean the kitchen,” π0.5 – a new model that uses co-training on heterogeneous tasks to enable broad generalization – breaks down the instruction into subtasks (“pick up the cup,” “wipe the counter”) and translates each into action trajectories, even in homes it has never seen before. It learns across morphologies – fixed arms, mobile bases, hybrid systems – and across modalities, including teleoperated demos, web-labeled images, and natural language instructions. Its performance doesn’t rely on memorization or manual programming; it emerges from broad, cross-embodiment learning. Ablation studies in the π0.5 paper show that removing cross-embodiment data leads to significant performance drops – directly validating the idea that embodiment diversity improves learning [16]. In short, Physical Intelligence’s robot foundation models (π, π0, π0.5) are not just VLA models; they are proof that morphology-agnostic, internet-style learning can work in robotics, unlocking scalable generalization through cross-embodiment training.
That’s why Lux bets on bodies - not just brains. Physical Intelligence (π) shows what’s possible when reasoning meets motion, and our portfolio reflects that belief. Multiply Labs brings robotic precision to pharma manufacturing, reducing contamination and cost in lifesaving therapies. Collaborative Robotics’ Proxie deploys trusted mobile manipulation in hospitals and warehouses alike. And Formic unlocks automation for SMBs with a robotics-as-a-service model that prioritizes usefulness as a prerequisite for intelligence.
Formic CEO Saman Farid believes that utility drives scale, and scale drives learning: “the only way to get deployed at scale is to be useful.” Rather than subsidizing robotic demonstrations in controlled labs, Formic deploys robots to do real work in messy, dynamic factories. Some are AI-enabled; others are not. But all deliver economic value from day one. That installed base then becomes a source of invaluable training data – not synthetic tasks, but edge cases from real-world operations. The insight: 90% of robotic training data is noise; only the edge cases teach. And those edge cases only surface when robots are deployed widely, across diverse physical contexts. Farid’s thesis reframes the AI robotics flywheel: don’t build data to train smarter robots, deploy useful robots to generate better data.
These are not just robots - they are real, embodied systems solving bottlenecks that software alone never could. The future isn’t just smarter AI. It’s AI with arms. These bets aren’t just alignment with our thesis – they’re early signals of where the stack is already unbundling.
The success of π’s VLA models mark a turning point – but also expose how fragmented and brutally hard the robotics stack really is. From top-of-stack model orchestration and semantic planning, down to data generation via teleoperation, annotation infrastructure, embodiment-specific retargeting, and kinematics alignment – robotics will inevitably unbundle. Just like in autonomy and VR, the winners won’t be those who try to do everything, but those who pick a layer and go deep: the Applied Intuitions of simulation, the Scale AIs of teleoperation data, or the Hugging Faces of embodiment-specific tuning. π0.5 is a compelling surrogate for progress, but it also raises the stakes. Robotics, like language before it, is moving toward scale – but unlike language, it faces gravity, friction, and failure in the real world.
Our thesis remains: intelligence is becoming cheap, but embodiment is not. The next wave of robotics success won’t just come from building humanoids, but from building the stack.
The Robotics Stack
Until now, there has been no clear, layered map for how robotics systems - from data collection to intelligent control - actually come together. So we built one.
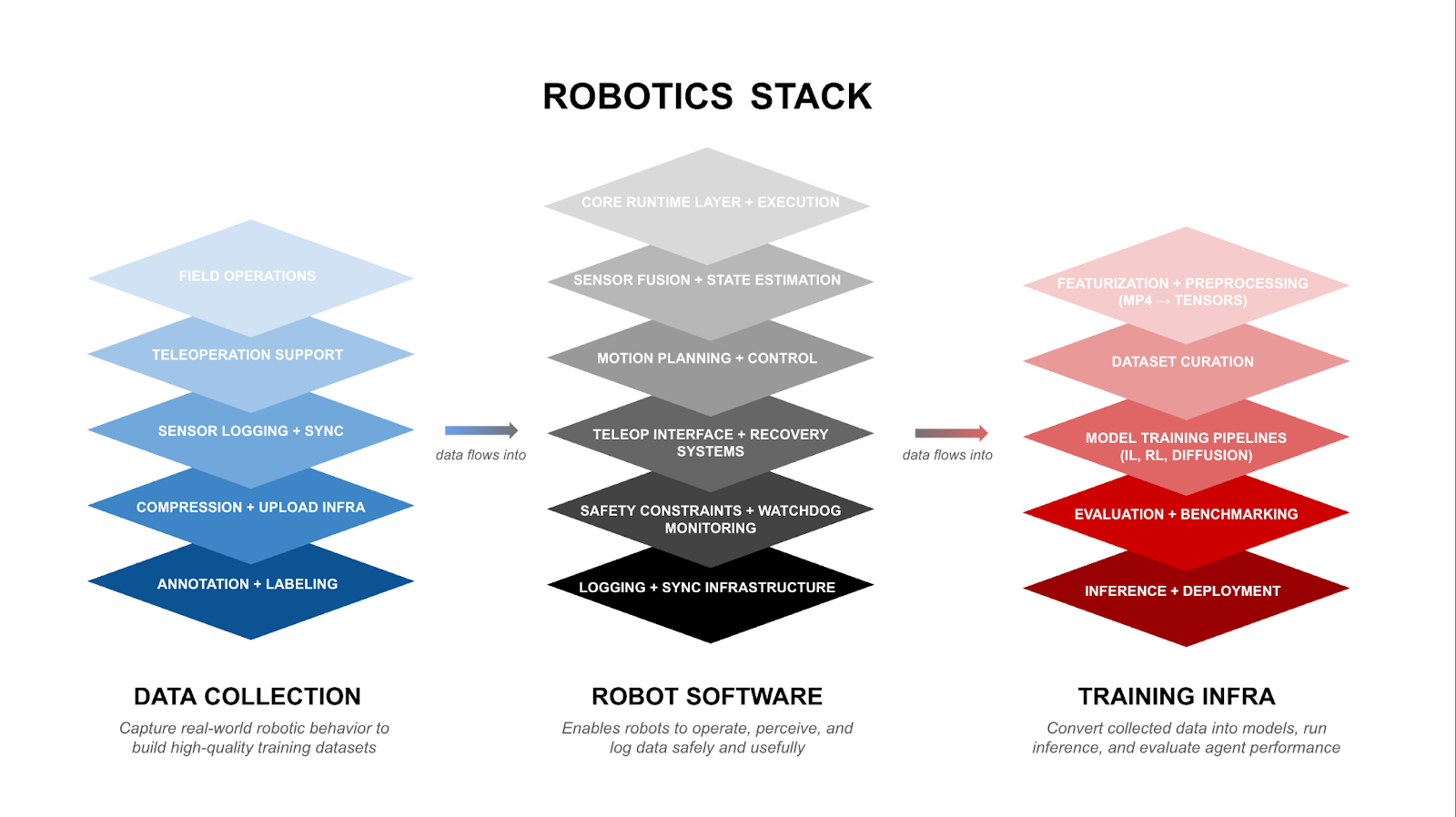
The Robotics Stack above breaks down the embodied intelligence engine into three core domains: Data Collection, Robot Software, and Training Infrastructure. It maps how real-world operations feed into intelligent behavior, and where critical infrastructure sits across the stack. Each layer feeds the next: data flows from deployed robots into structured training, enabling models like π0.5 to generalize across embodiments and environments.
If you're building in robotics - or trying to navigate where your company fits - hope this can serve as a blueprint, and please feel free to reach out to ghazwa@luxcapital.com.
Special thanks to Saman Farid (CEO and Founder of Formic Technologies) and Niccolò Fusai (Member of Technical Staff at Physical Intelligence) from the Lux portfolio for their insights and thoughtful contributions to this report.
